A quoi sert une “carte” des débats ?
Avant toute chose, précisions que l’approche de la cartographie de corpus dans laquelle nous nous plaçons n’a pas pour objectif d’obtenir une carte qui indiquerait ce qui est présent et ce qui est absent d’un ensemble de documents de manière exhaustive et définitive. Il s’agit encore moins de définir une norme concernant l’importance de chaque sujet au sein d’une carte. Au contraire, les cartes synthétiques d’un corpus sont considérées comme des représentations qui sont le fruit d’une interaction d’utilisateurs avec un corpus. Elles ont vocation à évoluer avec leurs futures interactions. Le principal intérêt à nos yeux de telles cartes est d’offrir un support de discussion capable, au cours du temps, d’intégrer les interrogations des différents acteurs amenés à utiliser de tels cartes. Une carte est un objet technique de médiation d’un dialogue et non un objet de légitimation d’une position. C’est une des raisons pour lesquelles les visualisations que nous proposons ici sont nécessairement provisoires.
Cadre méthodologique
Il existe deux grandes catégories de méthodes traditionnellement utilisées pour l’analyse de grands corpus de textes non structurés et pour l’identification des thèmes qu’ils traitent : l’analyse par co-termes (Callon et al. 1983) et le “topic modelling” avec des méthodes de type LDA (Blei et al. 2013). Dans ces approches, les sujets sont définis comme des ensembles d’expressions (multi-termes comme par exemple “gaz à effet de serre”, “vote blanc”, “impôts”, etc.), qualifiées par certaines statistiques, ces expressions provenant d’une liste définie au préalable. Pour notre analyse, nous nous sommes placés dans le cadre de l’analyse par co-termes, ce qui ne préjuge pas de l’intérêt d’autres types de méthodes qui pourront apporter un éclairage complémentaire.
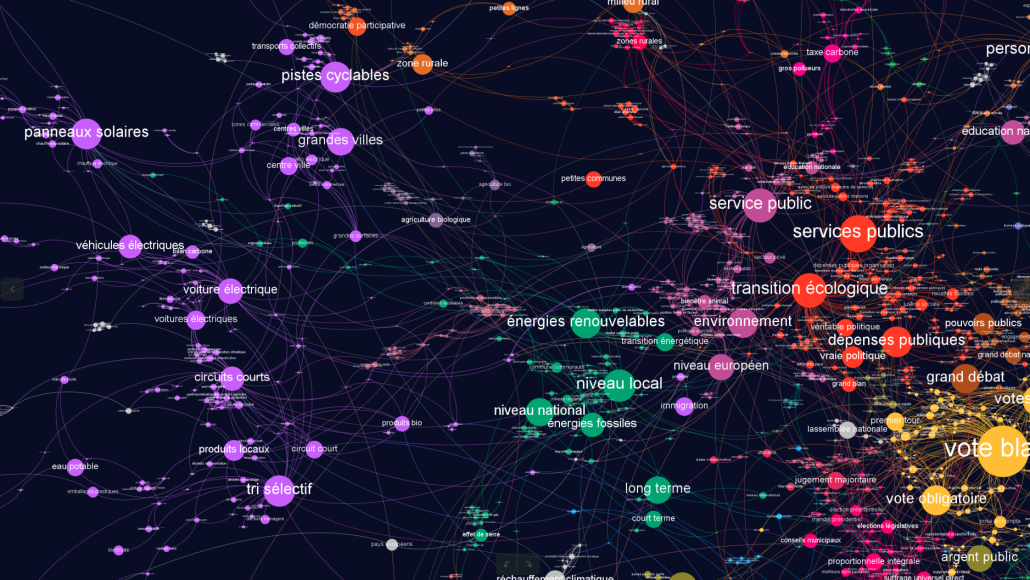
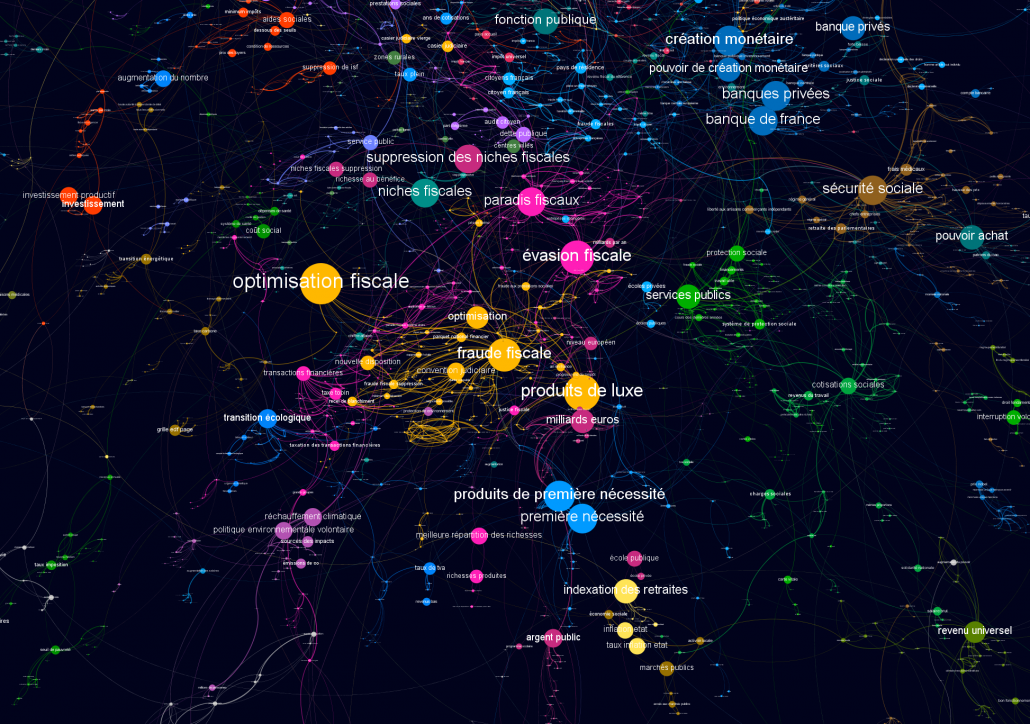
Dans le cadre d’une analyse par co-termes, la structure de chacun des ensembles d’expressions qui définissent les sujets est importante. Représentée comme un réseau d’interactions, elle donne des informations sur les sens dans lesquels sont compris ces mots et sur le degré de cohésion des sujets ainsi définis. D’autre part, chacun des sous-réseaux définissant un sujet prend part à un réseau plus large dans lequel on peut analyser l’interaction entre les différents sujets.
Etape 1 définition du corpus
La première partie de cette analyse a été effectuée avec l’aide de la plateforme d’analyse de masses de données Multivac de l’Institut des Systèmes Complexes de Paris Île-de-France (CNRS).
Le premier choix que nous avons à faire pour le traitement d’un corpus relatif à l’une des plateformes de débat est de définir ce qui sera considéré comme un document. Plusieurs choix sont possibles : prendre la contribution dans son ensemble et ses éventuels arguments/contre arguments, séparer propositions et argumentaires, s’intéresser aux paragraphes au sein des propositions, prendre uniquement les titres, etc. Chacun de ces choix donnera une teinte différente à la synthèse d’ensemble.
Après analyse des différents corpus, nous avons relevé une très grande hétérogénéité dans la longueur des textes proposés. Certains ne comportent qu’une phrase, d’autres ont plus de 10.000 signes. Quelle que soit la méthode utilisée, cette hétérogénéité introduit des biais de représentativité des contributions lors de leur agrégation ou du bruit dans les résultats. Afin d’atténuer les effets de cette hétérogénéité, nous avons choisi de prendre la phrase comme unité de contexte élémentaire et donc de calculer les interactions entre les mots au niveau des phrases. La première étape de traitement a donc été de réduire l’ensemble d’un corpus à un ensemble de phrases indépendantes. On remarquera ici que l’on travaille à un niveau de déstructuration maximale des contributions par rapport aux choix faits par les différentes plateformes qui toutes imposent un format et des catégories de contribution prédéfinis. C’est selon nous la meilleure manière de les rendre comparables bien que plusieurs choix pertinents soient possible pour l’unité de contexte élémentaire (on peut aussi choisir plusieurs phrases, un nombre donné de caractères, etc.). Cette déstructuration ne nous empêche pas de garder par ailleurs les contributions dans leur intégralité pour leur lecture lors de la phase finale d’exploration.
Enfin, dans les visualisations qui sont présentées ici, afin d’éliminer les réponses aux questions fermées de type “oui”, “non”, “c’est évident”, etc. dans les propositions de certaines plateformes, nous avons éliminé les phrases trop courtes. Pour ces cartes, nous avons filtré toutes les phrases de taille inférieure à celle-ci (100 caractères).
Etape 2 : définition de la liste d’expressions spécifiques aux propositions
La liste d’expressions à partir desquelles sont construits les sujets est obtenue par des méthodes de text-mining plus ou moins avancées dans les domaines du traitement du langage naturel (NLP) et de l’apprentissage machine.
Cette phase d’extraction terminologique est une étape importante du processus car elle conditionne ce que l’on pourra voir et ce qui sera absent de la représentation globale. Idéalement, une représentation globale d’un corpus via la méthode d’analyse par co-termes devrait permettre aux utilisateurs de la carte de mettre à jour en continu cette liste de mots-clés afin d’aller vers une représentation collective prenant en compte l’ensemble de leurs préoccupations. Soulignons que si l’établissement de cette liste d’expressions peut comporter une part de subjectivité, ce qui nous intéresse est la manière dont la méthodologie adoptée la structure in fine. Cette structuration est quant à elle le résultat d’une mesure objective. Un sujet mineur dans le corpus restera un sujet mineur dans la carte (peu connecté aux autres sujets, peu développé, avec peu de documents associés, etc.).
Pour l’extraction terminologique, nous avons d’abord annoté toutes les phrases des contributions en faisant au préalable de l’apprentissage machine à partir des ressources et formats du projet Universal Dependancies. À partir de cette annotation, il s’agit de définir les ensembles d’expressions qui constituent une unité sémantique valide comme “gaz à effet de serre” contrairement à “gaz à effet de”. Nous avons donc défini une combinaison de types de termes éligibles (composition de groupes nominaux) et extrait toutes les combinaisons jusqu’à une taille limite (fixée à 5 dans les exemples présentés ici). Nous avons ensuite considéré les quelques dizaines de milliers d’expressions les plus fréquentes (en général dépassant 3 à 5 occurrences).
Étape 3 : Construction du graphe de termes et visualisation
Nous avons calculé les interactions entre les expressions restantes au sein des corpus considérés comme la mesure de confidence entre deux expressions (maximum des probabilités conditionnelles d’avoir une expression sachant l’autre dans une phrase). Nous obtenons ainsi un graphe dont les nœuds sont les expressions et les liens leur relation de confidence.
Pour l’analyse de ce graphe nous avons utilisé le logiciel Gephi.
Dans Gephi, nous avons parcouru “à la main” les 5000 expressions les plus connectées de cet ensemble afin d’éliminer celles qui portaient peu d’information (exemple “même nombre”).
Sur le graphe constitué des expressions restantes, nous avons calculé la modularité à l’aide de l’algorithme de Louvain ce qui nous a donnée des groupes de termes candidats à la définition de sujets.
Nous avons également calculé le PageRank de chaque expression dans ce graphe afin de l’utiliser pour déterminer la taille des noeuds. Le pagerank est un algorithme qui indique l’importance d’un nœud dans un graphe au sens de la probabilité de tomber sur ce nœud lorsque l’on navigue au hasard. Dans cette navigation aléatoire la probabilité de passer d’un nœud à l’autre est conçue comme proportionnelle à la force des liens.
Pour finir, nous avons spatialisé ce graphe avec l’aide de l’algorithme Force Atlas 2 et colorisé de différentes couleurs les différents groupes de termes formant un sujet.
Description technique de l’extraction terminologique
Multivac DSL : Cluster basé sur un Cloud : Apache Hadoop (YARN/HDFS), Apache Spark, Apache Zeppelin,
Bibliothèque Scala/Python pour NLP/NLU distribué : Spark-NLP (Maziyar PANAHI est membre de ce projet)
Workflow Multivac implémenté pour ce traitement :
ETL : Extraction, transformation et préparation des données
- Lecture de tous les fichiers JSON/CSV
- Encodage
- Unification des titres, propositions, arguments, etc.
- Partitionnement des sortie
- Enregistrement des sous Parquet sur HDFS
NLP Pipeline
- Chargement des fichiers Parquet
- Annotation de documents
- Détection des phrases
- Création d’un corpus de phrases
- Extraction des tockens au format français (l’, air)
- Normalisation des tockens
- Chargement du modèle d’étiquetage POS (entraîné par Maziyar Panahi sur la base de la banque d’arbres française Universal Dependency)
- Extraction des la formule grammaticale (chunk)
- Filtrage (pas moins de 4 caractères et pas plus de 50 caractères)
- Construction d’une matrice de cooccurrence
- Calcule des mesures de confidence
- Export pour Gephi
Tous les logiciels utilisés dans ce processus (Multivac DSL et Spark-NLP) sont Open Source sous licence Apache.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
